Basic x86 Assembly Language Tutorial
TODO write an introduction and motivation.
Intro notes
- Will use Gnu AS (GAS) "like" assembler. The LLVM assembler on Mac OS X can be used as it has the same interface, similarly the MinGW assembler on Windows as I believe it is derived from GAS.
- We will use AT&T syntax rather than Intel, as this is the format compilers and disassemblers seem to output by default according to my limited experience so far.
Installing the required tools
Basically you need the gcc compiler (or an equivalent like clang with it's gcc frontend`).
On Mac OS X:
- You need to install Xcode with the Xcode command-line tools
On Ubuntu/debian Linux:
$ apt install build-essential gcc-multilib
On FreeBSD, it already comes with a compiler, but you will need gmake to build the examples in the repository:
$ sudo pkg install gmake
On Windows:
- Install the MinGW toolset
Once you've completed installation run the following to check you can access the required tools:
$ gcc --version
$ objdump --version
If you get output from both tools you are good to go.
Chapter 1: The smallest assembly language program we can get away with
Below is the smallest program we can write in assembly language. The heading says "get away with" because in order to be so small we are ommitting an important discipline required for writing reliable assembly language code - managing the stack - but this doesn't matter for now. We'll explain more on this later.
.text
.globl _main
_main:
movl $0, %eax
retl
It declares a main method that does nothing except immediately return a 0 exit status.
Save this to a file called main_method_return_0.s, then you can compile it by running:
$ gcc -m32 main_method_return_0.s -o main_method_return_0.out
Then execute and examine the exit status of the process to see if it worked:
$ ./main_method_return_0.out; echo "Exit status was: $?"
To see our output, we echo the value of the $? shell variable which always contains the exit status of the last program to run.
You should see it output:
Exit status was: 0
And with that, you've made your first program in assembly language. Not quite "Hello world", but we'll get there later.
Explanation
Let's examine this program line by line:
.text
This is a directive that declares the start of a section of program code. Executable program code is always placed into a text section. Other sections will be introduced later when we store data.
.globl _main
This uses another directive and is the first part of declaring our main function. main is the entry-point to our program. The globl directive makes the _main symbol visible outside of our code, which is generally referred to as exporting. This is necessary so that system code knows where to begin executing our program.
_main:
This declares the label _main. This is the symbol that was previously made visible to the linker using .globl. Although we will refer to our function as main there is a convention that function names are prefixed with an underscore. This will be better explained later when we cover "calling conventions".
At this point we have defined the empty shell of a program and the start of a function. Next we implement the body of our main function with an actual assembly language instruction:
movl $0, %eax
This uses the mov instruction to load the literal number 0 into AX - the "accumulator register".
We are working in 32-bit mode so the mov instruction is suffixed with an l for "long", which makes it the 32-bit version of the mov instruction. Rather than 64-bit, 16-bit or 8 all of which are options. More on that later.
Similarly, because we are using a 32-bit instruction we also need to access the AX register as a 32-bit value. We do this by prepending the register name with an e, thus eax.
retl
Finally, ret returns control to the system-code which called our main function. Effectively telling the CPU to continue executing where it left off before our main function was called.
If we want to set a different exit status we can change the value loaded into AX.
.text
.globl _main
_main:
movl $17, %eax # <--- we now return the exit code 17
retl
Note that we were able to add an inline-comment to the above example using a hash # character.
If we compile and run this version we should see it set an exit status of 17.
$ gcc -m32 main_method_return_0.s -o main_method_return_0.out
$ ./main_method_return_0.out; echo "Exit status was: $?"
Exit status was: 17
Key points
We have already covered a lot of points in this first small example.
In terms of program structure:
- We need to use the
.textdirective to place our program code in the correct section of the compiled executable - To make a function we name a block of code using a label e.g.
_main: - The
_mainsymbol needs to be exported using.globl _mainso the system knows the entry-point to our program - Non-executable code-comments can be added using a hash character
#
Then considering executable instructions:
- We need to be explicit that we are using 32-bit mode by prefixing
eto register names and suffixing instructions withl - To return a value from a function we need to place it into the
AXregister - We use the
retlfunction to exit our function and return to the code that called it
Exercises
1) An equivalent C program
Given this C program roughly equivalent to our example:
int main() {
return 0;
}
Save it to a file called main.c then compile it to assembly language form using:
$ gcc -S -m32 main.c -o main.s
Open main.s in your editor.
- What differences do you notice between this and our simple program?
- What changes in the output if you make the return value
17instead of0?
2) Disassembling true and false
Two of the most basic Unix system tools are the true and false commands. One returns an exit status of 0 and the other returns 1.
Using objdump disassemble these two binaries (*):
$ objdump -S /bin/true > true.s
$ objdump -S /bin/false > false.s
- Open the two
.sfiles in your editor. What observations can you make? - Why does
truereturn0andfalsereturn1?
(*) on Mac OS X objdump might produce simpler output if you pass the -macho option in addition to -S (this is short for Mach-O not machismo).
Chapter 2: Receiving input from the command line
In this chapter we are going to build the equivalent of the following C program:
int main(int argc, char *argv[]) {
return argc;
}
Command line arguments are passed to a C or assembly language program via two parameters to the main function. The first parameter argc is an integer which will contain the count of arguments passed on the command line. The second parameter argv is an array containing the command-line argument strings.
In this example, we continue abusing the exit status value as a way to get output from our programs by returning the count of input arguments argc as the exit code.
Here is the assembly language version:
.text
.globl _main
_main:
# Set up the stack
pushl %ebp
movl %esp, %ebp
# Load the value of argc into eax
movl 8(%ebp), %eax
# Return to calling code
popl %ebp
retl
Save this to a file called cli_input.s, then you can compile it by running:
$ gcc -m32 cli_input.s -o cli_input.out
Then execute and examine the exit status of the process to see if it worked:
$ ./cli_input.out; echo "The number of arguments was: $?"
You should see the output:
The number of arguments was: 1
Eh!? But we haven't passed any arguments!! It turns out there is always one argument in argv even if we haven't passed anything on the command line and that is the file path of the program itself. We will see what this looks like in a later chapter. Let's run it again and pass our own arguments.
$ ./cli_input.out 1 2 3; echo "The number of arguments was: $?"
The number of arguments was: 4
We now have three arguments in addition to the program path so we correctly see the number 4 as our exit status.
Explanation
Let's break down the body of our new main function line-by-line.
# Set up the stack
pushl %ebp
movl %esp, %ebp
These two lines are very important. They are one half of the missing stack management discipline alluded to in chapter 1, where we omitted them intentionally to keep our program as small as possible. From now on they will appear together at the beginning of all of our functions.
The important role they play is to set aside an area of what is known as stack memory, where our function can store any local variables it might need while it is executing. The word stack here refers to the classic data structure where you push and pop values on and off the top of a collection, and only ever operate on whichever value is currently at the top.
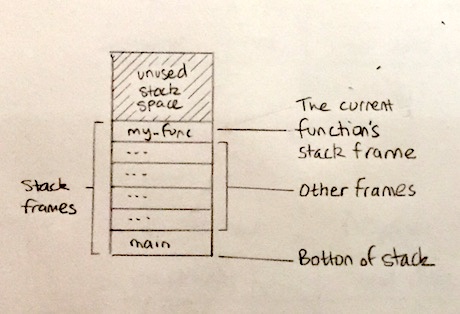
This area of memory dedicated to our function, within the stack, is referred to as a stack frame. Each function in a program has its own stack frame. Because functions can call other functions in a kind of chain, there may be many stack frames on the stack at any one time.
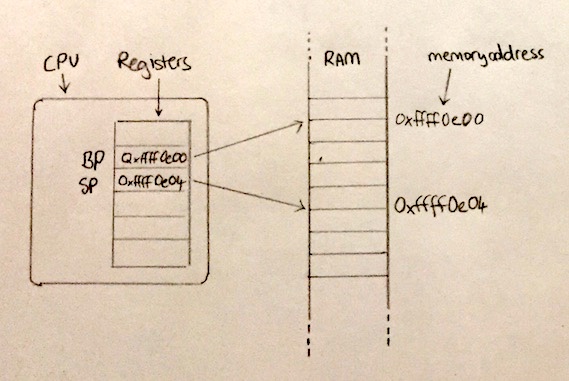
⚠️ TODO ^^^ the addresses are the wrong way around, SP will always be <= BP
The base-pointer (BP) and the stack-pointer (SP) are two registers dedicated to managing the stack. Their existence shows that the concept of having a stack is not just a software mechanism, but an idea actually baked into the CPU hardware architecture.
BP holds the memory address relative to which our function will look up stack data it has access to. We will see an example of this shortly.
SP holds the memory address of the top of the stack. It is used to quickly find the next free memory when we need to push some data onto the stack.
The area of memory between the addresses in SP and BP contains all stack data local to the currently executing function.
So what do these two lines actually do?
pushl %ebp
This line saves the address of the calling function's base pointer so it can be restored later when we return. pushl copies the current value of %ebp onto the top of the stack, then updates the address in %esp by the size of %ebp, so it continues to point to the top of the stack. Because we are in 32-bit mode the size of %ebp will be 4 bytes and so %esp will be changed by 4.
movl %esp, %ebp
This line copies the address stored in SP to BP, which effectively updates the base pointer to refer to the top of the stack. Having done this our function can now safely push any local data it might need.
Moving on to the actual body of our function:
# Load the value of argc into eax
movl 8(%ebp), %eax
There is some new syntax here. Putting parentheses around %ebp accesses the value stored at the address held in BP. Prefixing with 8 offsets the address in BP by +8. So we are looking up a value in the stack relative to the base pointer.
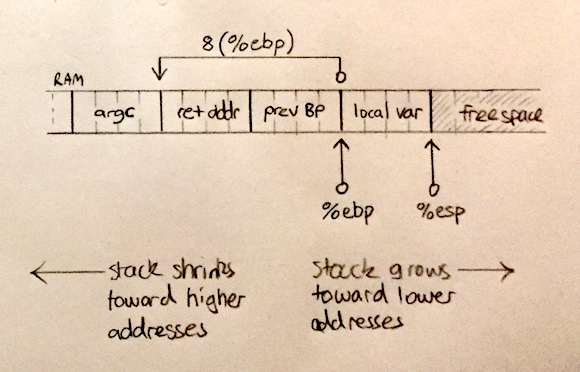
You might notice something a little weird here: we are calculating a higher memory address to reach backwards in the stack to where calling code placed our function parameters. This is because stack grow downwards, not upwards as would be our intuition. This is just the way a processes memory is organised. Most of the time this does not matter, you can just visualise the stack growing up and shrinking down. The thing to remember is:
- Positive offsets reach back towards function arguments and
- Negative offsets reach forward to local variables
The reason we offset by 8 from the BP, is that inbetween the function parameter and BP there are two values:
- The return address - the address of the next instruction in calling code after it called our function (labelled
ret addrin the diagram above) - The previous address of BP - we saved this when we called
pushl %ebpat beginning of our function
Now we reach the other half of the stack management discipline - reseting the stack and returning:
# Return to calling code
popl %ebp
retl
Because we did not allocate any local variables, the value at the top of the stack is the previous address of the BP. We use popl to load it back into %ebp and increment %esp (remember addresses going up in value go down the stack).
Lastly, we use retl to return control to calling code. Given our new awareness of the stack, we can explain in more detail what this is doing. Having popped the previous value of BP off the stack, the data at the top is now the return address. What ret does is pop that address off of the stack and load it into the instruction pointer register (IP).
TODO final diagram showing we have returned and our now unallocated stack frame for main
Key points
Here we are again. We have a small example and yet there are loads of interesting facts learned.
- Arguments from the command-line are passed to
mainas function parameters (argcandargvin C) - The stack is a per-process area of main memory used to maintain local state in functions
- We maintain the stack using the base-pointer (BP) and stack-pointer (SP) registers
- When we enter a new function we set up a new stack frame by storing the previous value of BP then pointing it to the top of the stack
- We address values in the stack relative to the base-pointer (BP)
- Stack memory is arranged such that the bottom is at a high address and it grows towards lower addresses.
- Addresses of function parameters will have positive offsets and local variables will have negative offsets
- To address the first function parameter we have to offset by 8 to skip over the saved base-pointer and return instruction-pointer
- Before a function can return, the stack must be restored to the state it was in when the function was called
Exercises
1) Don't count the program path
Update the example code to deduct 1 from the count in argc, so we only see the number of actual arguments we passed on the command line.
The subl instruction will let you subtract a value from another held in memory.